

Introduction
Effective redundancy planning is more than just a numbers game. Imagine a critical e-commerce website crashing during a flash sale, or a manufacturing plant grinding to a halt due to a server failure. These scenarios highlight the very real and often costly impact of system failures. When these occur, businesses scramble, and often realize too late that they hadn’t adequately prepared for when things go wrong.
The concepts of N+1 and 2N redundancy are often presented as simple mathematical equations, but in reality, they represent vastly different philosophies regarding reliability and risk management. While both strategies aim to minimize downtime, their approaches, costs, and suitability vary significantly. Choosing the right approach requires careful consideration of factors beyond just the number of components involved.
This article will delve into the nuances of N+1 and 2N redundancy, explaining what they entail and exploring when each is most appropriate. We’ll go beyond the basic math to uncover the hidden complexities and crucial considerations that determine the true effectiveness of these redundancy strategies. Our goal is to provide you with the insights needed to make informed decisions about protecting your critical systems and ensuring business continuity.
N+1 Redundancy
N+1 redundancy is a widely used strategy designed to ensure system availability without incurring the high costs associated with fully duplicated systems. In essence, N+1 means that for every ‘N’ components required to run a system at its designed capacity, one additional component (+1) is added as a backup.
This approach balances the need for reliability with budgetary constraints, making it an attractive option for many organizations. Should one of the primary components fail, the redundant component seamlessly takes over, minimizing downtime.
The primary advantage of N+1 lies in its cost-effectiveness. By adding only one extra component, the initial investment is significantly lower compared to strategies like 2N, which require a complete duplication of the entire system. This reduced hardware footprint also translates to lower energy consumption, cooling requirements, and overall operational expenses.
Furthermore, N+1 can lead to efficient resource utilization during normal operation. The redundant component can often be used to handle peak loads or perform non-critical tasks, increasing overall system efficiency. This approach is especially suitable for systems where a brief period of degraded performance during a failure is acceptable.
However, N+1 is not without its limitations. The most significant concern is the potential for a single point of failure. If the redundant component itself fails before one of the primary components fails, the system is left vulnerable. Moreover, when a primary component fails and the redundant component takes over, the system operates at a reduced capacity.
This can lead to performance degradation, impacting user experience or overall system throughput. The time it takes for the system to detect the failure and switch over to the redundant component (failover time) can also result in a period of downtime, depending on the system’s design and configuration. Therefore, organizations must carefully consider these limitations and implement thorough monitoring and testing procedures, as well as comprehensive redundancy planning to mitigate the risks associated with N+1.
| Advantage | Limitation |
|---|---|
| Cost-effective | Potential single point of failure |
| Efficient resource utilization | Reduced capacity during failure |
| Lower initial investment | Possible downtime during failover |
2N Redundancy
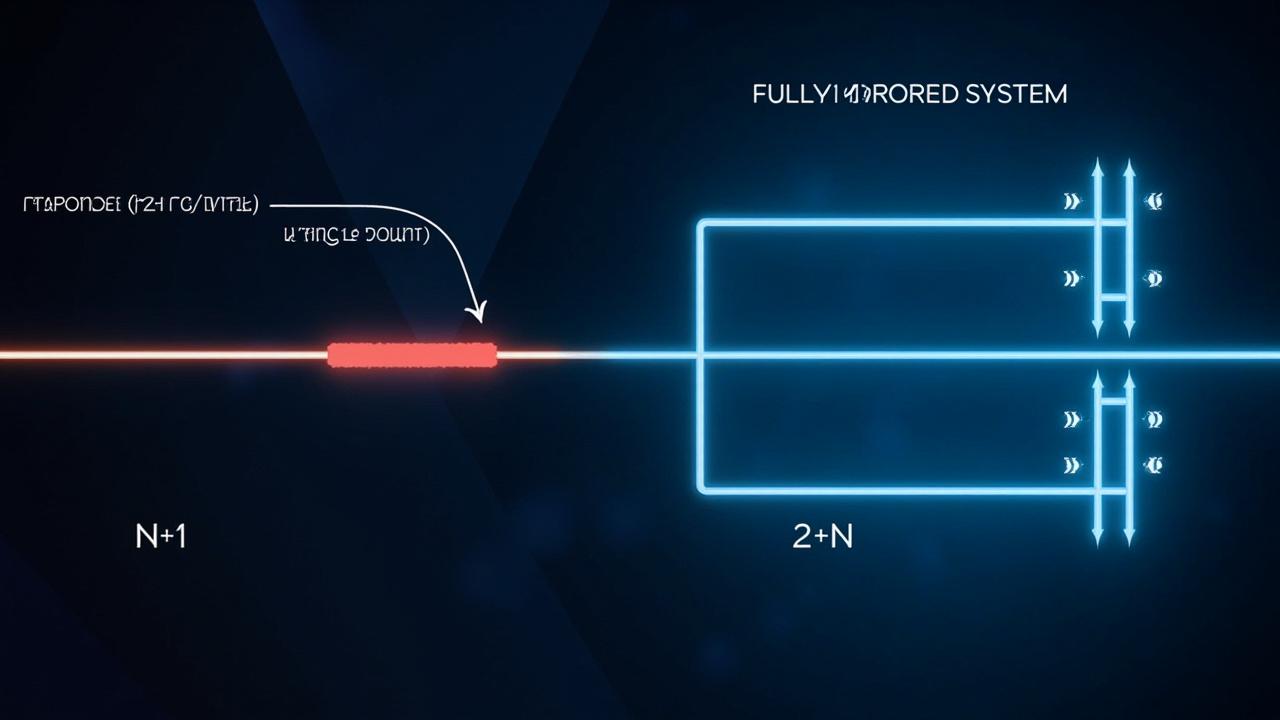
With 2N redundancy, we move into the realm of mirrored systems, prioritizing near-uninterrupted operation, and providing the highest possible level of resilience. Unlike N+1, which relies on a single backup, 2N involves deploying a completely duplicated environment, running in parallel with the primary system. This means every component, server, network connection, and power supply is mirrored, effectively creating an exact replica.
In normal operation, both systems are active, and data is typically synchronized in real-time or near real-time. This approach offers a significant advantage when failure occurs because the secondary system is already up and running.
The key benefit of 2N redundancy is the promise of near-instantaneous failover. When the primary system experiences an issue, the secondary system seamlessly takes over, minimizing disruption. This is crucial for applications where even a few seconds of downtime can have severe consequences, like financial trading platforms, air traffic control systems, or critical healthcare infrastructure.
Because both systems are active, failover can often be automated and imperceptible to users. However, the high level of protection comes at a considerable price.
The most significant drawback of 2N is the high initial investment. Deploying and maintaining two complete systems doubles the hardware and infrastructure costs. Resource utilization can also be a concern. Under normal circumstances, the redundant components may be largely idle or performing duplicate tasks, leading to questions about efficiency. However, for mission-critical applications where downtime is unacceptable, the cost is easily justified. Therefore, *redundancy planning* must include a careful consideration of these costs alongside the potential costs of downtime.
| Aspect | Description |
|---|---|
| Core Concept | A completely duplicated system running in parallel |
| Failover Speed | Near-instantaneous |
| Primary Use Cases | Mission-critical systems, financial transactions, life support |
| Cost | High initial investment due to doubled hardware and infrastructure |
The Failure Domain
The concept of a failure domain extends beyond the simple accounting of redundant components. It forces us to consider the blast radius of any potential failure. A failure domain encompasses all the components and systems that could be affected by a single point of failure. While N+1 and 2N redundancy strategies focus on component-level backups, they often overlook shared resources and infrastructure dependencies, leading to potentially catastrophic outcomes.
For example, consider a seemingly robust 2N system with complete hardware duplication. However, if both systems rely on the same power source, network switch, or cooling system, a failure in any of these shared resources can bring down both systems simultaneously, effectively negating the benefits of the 2N setup.
In this scenario, the failure domain extends beyond the individual servers to include the power and network infrastructure. This underscores the importance of identifying and addressing these shared dependencies as part of comprehensive redundancy planning.
Here are some examples of shared resources that can compromise even the most robust redundancy strategies:
- Power Distribution Units (PDUs): Both redundant systems plugged into the same PDU.
- Network Switches: Reliance on a single switch for network connectivity.
- Cooling Systems: Shared cooling infrastructure leading to overheating during a failure.
- Internet Service Provider (ISP): Both systems relying on the same internet connection.
Mitigating risks related to failure domains requires a holistic approach that extends beyond component-level redundancy. Some strategies include:
- Diversification: Using multiple providers or vendors for critical resources.
- Segmentation: Isolating systems and resources into separate failure domains.
- Geographic Distribution: Distributing systems across multiple physical locations.
- Independent Infrastructure: Ensuring each redundant system has its own dedicated power, network, and cooling infrastructure.
By carefully analyzing and addressing potential failure domains, organizations can ensure that their redundancy strategies provide true resilience and protect against unforeseen disruptions.
Real-World Redundancy Planning
When selecting a redundancy strategy, it’s crucial to move beyond theoretical formulas and consider the practical implications for your specific environment. The most robust system on paper can still fail if it doesn’t align with your business needs and constraints. Several key factors warrant careful consideration when developing a comprehensive approach to keeping your systems online.
First and foremost, understanding the business impact of downtime is paramount. Quantify the financial losses, reputational damage, and potential legal ramifications associated with system outages. This involves:
The criticality of the system plays a vital role in determining the appropriate redundancy level. A non-essential system that experiences occasional downtime might be perfectly acceptable with N+1 redundancy, but the same approach would be disastrous for a life-critical application. Alongside business impact, budget constraints inevitably influence the decision-making process.
While 2N redundancy offers the highest level of protection, it also demands a significant investment in hardware, software, and ongoing maintenance. Organizations often need to find a balance between desired resilience and available resources. Careful financial modeling is essential to determine the most cost-effective strategy for risk mitigation.
Furthermore, regulatory requirements may mandate specific levels of redundancy for certain industries or systems. Financial institutions, healthcare providers, and government agencies often face strict compliance standards that dictate minimum uptime and data protection measures. Neglecting these requirements can result in severe penalties and legal repercussions. Lastly, consider maintenance and operational overhead associated with different redundancy strategies.
Complex systems like 2N are costly to implement and require specialized skills to manage and maintain. The additional equipment needs more power, space and cooling. Simplify maintenance tasks through proactive measures, such as:
Taking a holistic approach that considers these elements is key to successful *redundancy planning*.
Beyond N+1 and 2N
While N+1 and 2N configurations represent common approaches to system design for fault tolerance, they don’t represent the only strategies available. The optimal solution for ensuring business continuity often involves a more nuanced, tailored approach that leverages hybrid models and advanced techniques to achieve the desired level of resilience. Businesses should carefully assess the spectrum of options available to them as they consider their strategies for ensuring continuity.
N+M Redundancy
One such hybrid model is N+M redundancy. In this configuration, ‘N’ still represents the required capacity to meet the demands of the workload, but instead of a single redundant component, ‘M’ represents multiple redundant components. This offers a middle ground between the economy of N+1 and the high availability of 2N.
For example, a data center might utilize an N+2 configuration for its cooling systems, where N represents the cooling capacity needed under normal conditions, and the two additional units ensure adequate cooling even if one fails and maintenance can be performed without any service disruption.
This approach can be highly effective in scenarios where the cost of a complete 2N setup is prohibitive, but the risk associated with a single point of failure in an N+1 system is unacceptable.
Geo-Redundancy
Another advanced strategy involves geo-redundancy, where systems and data are distributed across geographically diverse locations. This protects against localized disasters such as power outages, natural disasters, or regional network failures. A company might replicate its databases and applications in two or more separate data centers located hundreds or thousands of miles apart.
In the event of a failure at one location, the other location can seamlessly take over, ensuring minimal downtime. Of course, the impact of latency on application performance must be factored into such a solution, and it might also make sense to implement a cloud based solution to provide access to a greater geographical area. Geo-redundancy represents a significant investment, but it can be essential for organizations with stringent uptime requirements and a high tolerance for latency.
Active-Active vs. Active-Passive
Finally, it’s crucial to consider the operational modes of redundant systems: active-active versus active-passive. In an active-active configuration, all redundant components are actively processing workloads simultaneously, maximizing resource utilization and providing near-instantaneous failover. However, this requires careful load balancing and data synchronization to ensure consistency. In contrast, an active-passive configuration involves one system actively processing workloads while the redundant system remains on standby, ready to take over in the event of a failure.
This approach simplifies management but may result in a brief period of downtime during failover. Regardless of the specific redundancy model chosen, comprehensive data protection is paramount. This includes implementing robust backup and recovery strategies, as well as data replication techniques, to ensure that data can be quickly restored in the event of a failure or data loss event. Effective redundancy planning encompasses not just infrastructure, but also data integrity and availability.
Case Studies
Here are some case studies that exemplify the application of N+1 and 2N strategies. By analyzing these examples, we can better understand the nuances and practical considerations involved in choosing the right approach. These scenarios will highlight the importance of understanding the specific context and how overlooking key factors can lead to unexpected outcomes.
Hospital Life Support Systems: 2N in Action
A large metropolitan hospital implemented a 2N redundancy strategy for its life support systems. This included ventilators, cardiac monitors, and emergency power generators. The decision was driven by the critical nature of these systems; any downtime could have immediate and potentially fatal consequences for patients. The 2N architecture ensured that a fully mirrored system was always online and ready to take over seamlessly in case of a failure in the primary system.
Regular testing and maintenance were performed on both the primary and secondary systems to guarantee their operational readiness. This commitment to 2N resulted in near-zero downtime for life support, providing peace of mind to both medical staff and patients. This highlights how crucial it is to implement 2N in scenarios where any downtime can have fatal consequences.
Small Business Web Server: N+1 Adequacy
A small e-commerce business opted for an N+1 redundancy strategy for its web server infrastructure. They understood the potential impact of downtime on their sales but had budget constraints. Their N+1 setup consisted of a primary server handling all website traffic and a single standby server ready to take over in case of a failure.
The failover process was automated, but it took approximately 15 minutes to complete. While this resulted in some lost transactions during failover, the business deemed it an acceptable trade-off compared to the much higher cost of a 2N system. This case illustrates how N+1 can be a viable option for businesses with less stringent uptime requirements and tighter budgets, particularly with effective redundancy planning.
Data Center Power Outage: The Importance of Failure Domains
A data center employed a 2N redundancy configuration for its power supply, with two independent power feeds and UPS systems. However, a localized fire in the main distribution frame (MDF) room took out both power feeds simultaneously. Despite the 2N design, the entire data center experienced a complete power outage. This incident revealed a critical flaw: the failure domain was not properly considered.
Both power feeds converged in a single physical location, negating the benefits of redundancy. The lesson learned was that even with 2N, it’s vital to diversify infrastructure elements and avoid single points of failure that can compromise the entire system. It’s imperative to consider all aspects of infrastructure when implementing a solid redundancy planning strategy.
Conclusion
Ultimately, the decision between N+1 and 2N redundancy models, or even exploring hybrid approaches, extends far beyond simple calculations. It demands a holistic understanding of your organization’s unique operational landscape.
There is no universal solution; instead, the optimal strategy is one meticulously tailored to mitigate specific risks, align with budgetary realities, and uphold critical service level agreements. This necessitates a deep dive into the potential impact of downtime, the criticality of the systems in question, and the practicalities of ongoing maintenance and management of redundant systems.
Selecting the appropriate redundancy strategy is not a task to be taken lightly. It requires careful consideration of your business priorities, technical capabilities, and financial constraints. An effective strategy anticipates potential failure scenarios and outlines clear procedures for failover and recovery.
This might involve elements like geo-redundancy to protect against regional disasters, or active-active configurations to maximize resource utilization. Thorough risk assessment, coupled with a strong understanding of the available technologies, will guide you toward a resilient and cost-effective solution. Moreover, the overall strategy should include aspects of data redundancy, including efficient backup and recovery solutions.
In conclusion, remember that N+1 and 2N offer distinct approaches to achieving system resilience, and that comprehensive redundancy planning considers the entire operational ecosystem. We encourage you to look past the basic formulas and delve into the underlying factors that drive effective redundancy.
By considering the full spectrum of risks, costs, and business requirements, you can make informed decisions that safeguard your critical systems and ensure business continuity. If you’re ready to take the next step in fortifying your infrastructure, contact us today for a personalized consultation, where we can help you craft a redundancy strategy that aligns perfectly with your organizational needs.
Frequently Asked Questions
What is redundancy planning and why is it important for my business?
Redundancy planning is the process of creating backup systems and procedures to ensure business continuity in the event of a failure or disruption. This is crucial for businesses because it minimizes downtime, protects critical data, and maintains operational efficiency even when unexpected problems occur. By implementing redundancy, a company can avoid significant financial losses and damage to its reputation.
What are the different types of redundancy planning strategies?
Redundancy planning encompasses various strategies, including hardware redundancy using mirrored servers or RAID arrays, software redundancy through virtual machines or replicated databases, and geographic redundancy involving backup locations in separate regions. Data redundancy ensures copies of critical information are stored in multiple locations.
Network redundancy implements multiple network paths. The specific strategy depends on the criticality of the system and the potential impact of failure.
How do I identify critical systems and data that need redundancy?
Identifying critical systems and data involves a thorough business impact analysis. This process assesses which systems and data are essential for core business functions and the financial and operational consequences if they become unavailable.
Focus is on systems responsible for generating revenue, processing orders, or maintaining customer relationships. Once the critical systems are pinpointed, the corresponding data should be identified and prioritized for redundancy planning.
What are the key steps involved in creating a redundancy plan?
Creating a redundancy plan involves several key steps, starting with defining the scope and objectives. Then, perform a risk assessment to identify potential threats and vulnerabilities. Next, select appropriate redundancy strategies for critical systems and data.
Subsequently, document the plan meticulously, including procedures for failover, recovery, and testing. Finally, communicate the plan to all relevant personnel and conduct training to ensure everyone understands their roles.
How often should I review and update my redundancy plan?
Redundancy plans should be reviewed and updated at least annually, or more frequently if there are significant changes to the business, IT infrastructure, or risk landscape. Regular reviews ensure the plan remains relevant and effective.
Factors that may trigger a review include changes in business operations, new technologies being implemented, or the discovery of previously unidentified vulnerabilities. Testing the plan periodically is also vital to confirm its functionality and identify any necessary adjustments.


